1
Dual Mismatch: Why VLMs Do Not Directly Become VLAs
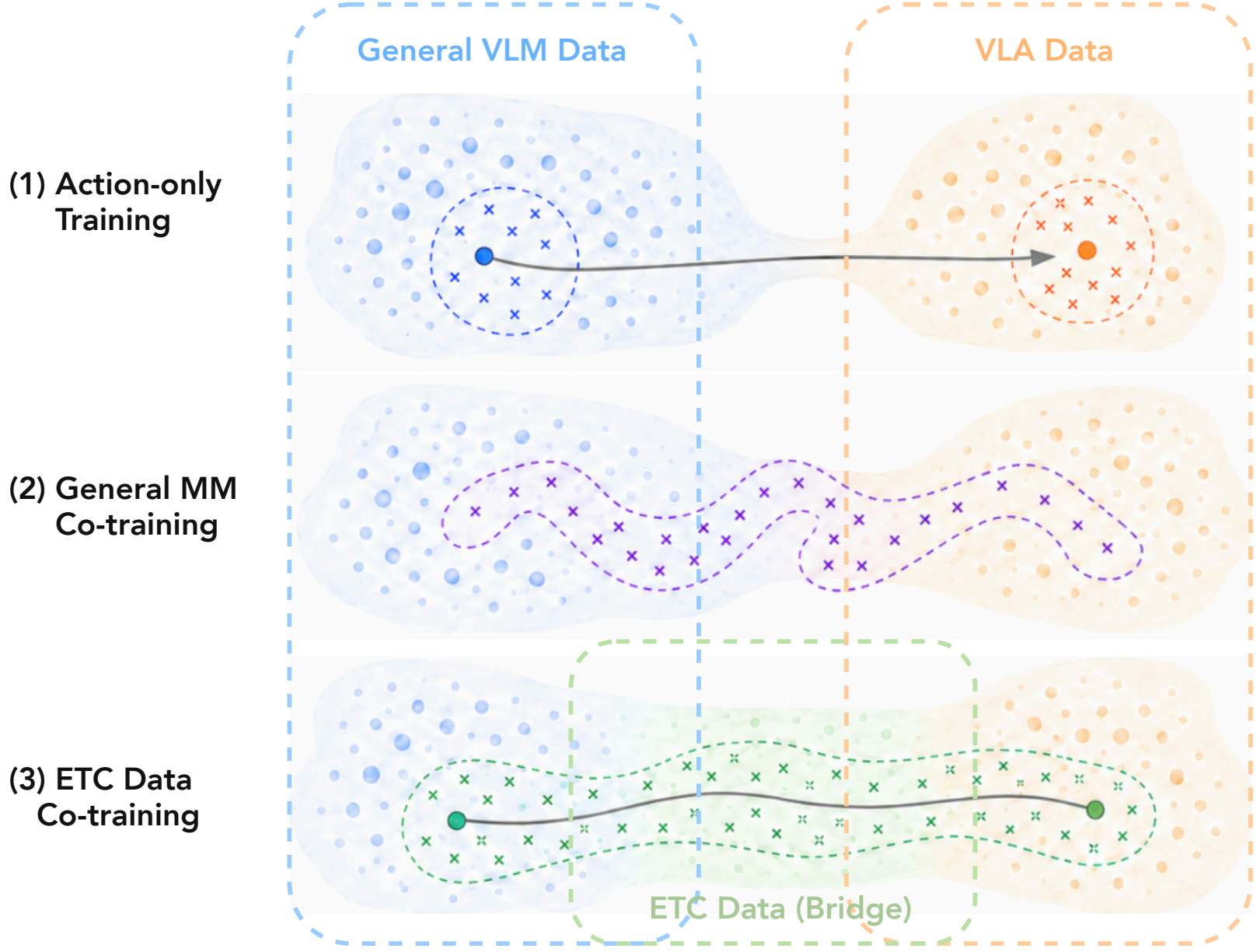
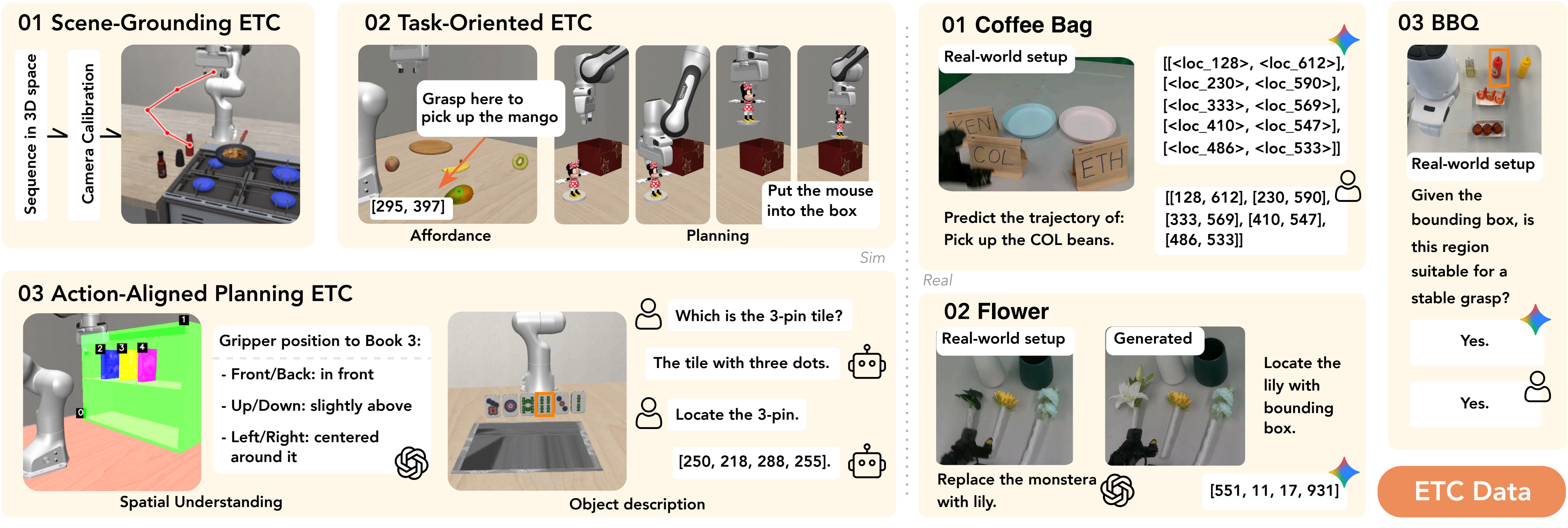
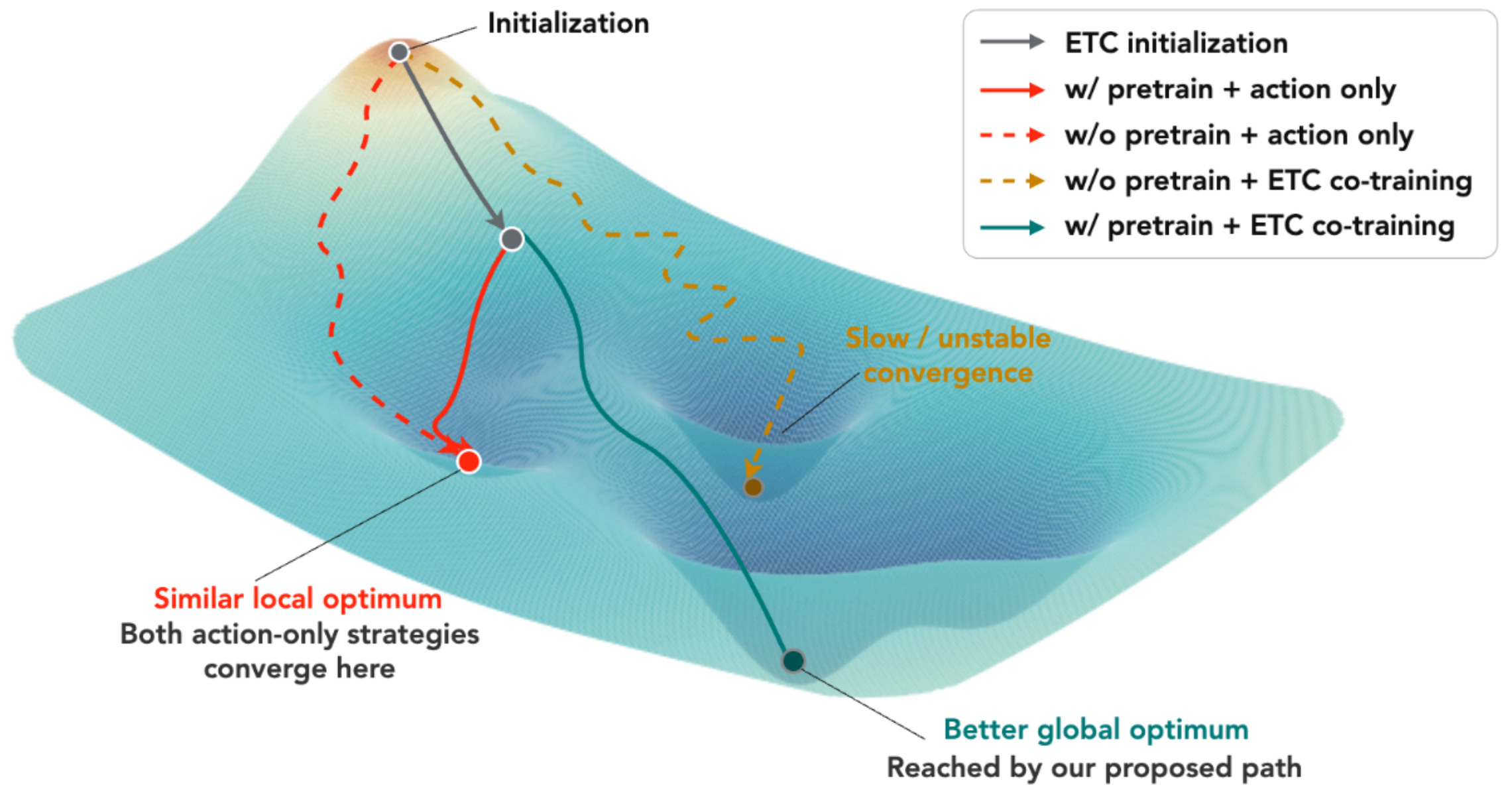
VLM-to-VLA adaptation must cross two mismatches at once: the distribution gap between general web-scale vision-language data and embodied robot scenes, and the objective gap between language understanding and executable action prediction. Action-only training jumps directly across both gaps, while generic multimodal co-training remains distant from robot manipulation. ETC provides the missing intermediate supervision by sharing embodied scene semantics with robot action data while retaining the familiar VLM objective.